Der Aufbau eines MSCS stellt unter Windows Server 2012 R2 keine Herausforderung dar, solange man ihn auf „bare metal“ im normalen Office Netz installiert. Wie das im Einzelnen durchzuführen ist, wird hier vorausgesetzt.
Die Installation in der VMware sowie hinter einer Firewall in einem geschotteten Netzsegment erfordert ein paar zusätzliche Maßnahmen. Im Folgenden geht es um diese Besonderheiten.
Kapitel 1: Shared Storage in der VMware
Ein Cluster in der VMware benötigt mindestens drei (!) gemeinsame Festplatten(-arten), angebunden via SCSI, iSCSI oder FC.
Dies sind eine oder mehrere Datenplatte(n) mit den Daten, die von beiden Knoten erreichbar sein müssen sowie eine Quorum Disk. Letztere kommt mit einer denkbar kleinen Größe von einigen hundert MB aus. Hier loggen die Knoten ihre jeweiligen Aktivitäten, so dass der jeweils andere Knoten im Falle eines Umschaltvorgangs den Status erkennen und übernehmen kann.
Die dritte Plattenart muss eine klassische Platte im SAN sein, die also ebenfalls von beiden Knoten gesehen werden kann aber für die geclusterten Inhalte keine Bedeutung hat und auch nur dem ESX Host bekannt gemacht wird. Deren Zweck wird weiter unten erläutert.
Im Falle einer Bare-Metal-Installation stellt das alles kein Problem dar, da die FC-Controller unmittelbar zur Verfügung stehen. In einem VMware Environment, steht der physikalische Controller zwar dem Hypervisor zur Verfügung, wird an das Gast-OS aber als LSI oder Paravirtual Controller weitergereicht. Für letzteren bringen die VMware-Tools sogar einen eigenen Treiber mit.
(!) Mit virtuellen HD-Controllern funktioniert das Clustering nicht!
Die Platten müssen zwingend als RDM (RAW Device Manager) abgebildet werden.
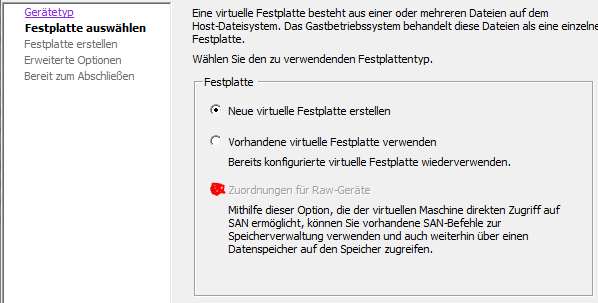
(Hier ausgegraut, weil keine physikalischen Platten mehr zur Verfügung stehen)
Der auszuwählende SCSI Controller muss zwingend LSI Logic SAS sein und „physisch“.
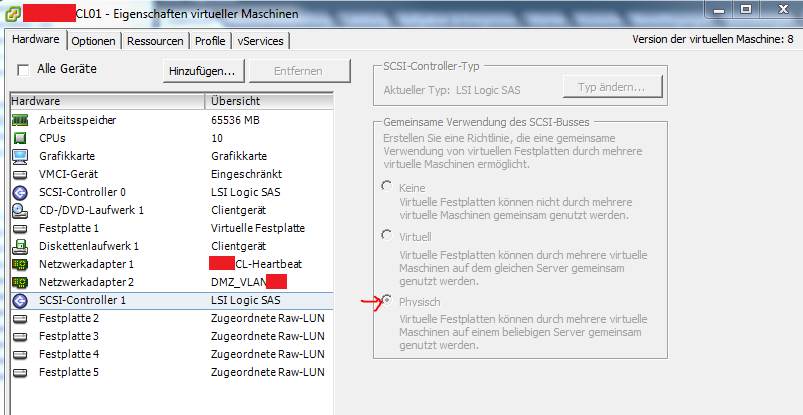
In unserem Beispiel sehen wir eine lokale Platte für das OS, plus drei Datenplatten plus eine Quorum (die sich wie eine Datenplatte darstellt).
Die oben erwähnte „dritte Platte“ ist hier nicht zu sehen.
 Hier sieht man alle am Host angebundene LUNs.
Hier sieht man alle am Host angebundene LUNs.
Schaut man genauer hin, erkennt man die LUNs 110 bis 114:
Schaut man sich die Properties der Platten an den Clusterknoten an, sehen alle gleich, nämlich so aus:
![]()
D.h. alle VMDK Dateien liegen auf der LUN 114.
Wie kommt das?
Bei der Erstellung eines physikalischen RDM Devices wird am Ende gefragt, wo die VMDK Datei gespeichert werden soll. Hier wird bei einer normalen Single-Host installation i.d.R. „zusammen mit der virtuellen Maschine“ angeklickt. In diesem Fall ist das ungünstig, da die virtuelle Maschine auf dem lokalen Speicher des Hosts liegt und der zweite Clusterknoten dorthin keinen Zugriff hat.
Das bedeutet, dass man für die VMDK Dateien der zu sharenden Platten eine zusätzliche SAN Platte benötigt. In unserem Fall ist das die LUN114.
Das ist neben der lokalen Platte dann auch die einzige, die man im Ressourcenfenster der Gast-Systeme (Nodes) sehen kann:

Hat man alles richtig gemacht, findet man die VMDK Dateien aller shared Devices dort:

Zur Zuweisung der Platten auf dem zweiten Node einfach

markieren und die entsprechende VMDK-Datei auf LUN114 auswählen.
Im Disc-Management der Gastsysteme sind die Platten danach sichtbar:

Werden sie auf dem ersten Clusternode dann partitioniert, formatiert und mit Laufwerksbuchstaben und Volumenamen versehen, sieht man auf dem zweiten Knoten die Erstellung simultan. D.h. diese Platten sind nun für beide Knoten sichtbar, ganz so wie an zwei physikalischen Maschinen. Ein MPIO Feature incl. Hardwaretreiber wie bei Baremetal Servern wird hier nicht installiert und verwendet!
Damit sind die Platten für das Clustering vorbereitet und der MSCS würde auch wie gewünscht laufen. Leider gibt es noch Schwierigkeiten, wenn einer der ESX – Hosts rebootet werden muss. Dieser will zunächst alle verfügbaren LUNs allokieren, stellt aber fest, dass diese schon vom anderen Knoten allokiert sind und läuft ca. 30 Min. durch Retries und Timeouts. Um dieses zu verhindern muss man dem ESX Host die Platten bekannt machen, um die er sich nicht zu kümmern braucht, weil sie für die Gastsysteme reserviert sind.
Dazu muss man sich via SSH an den Hosts anmelden und auf der Kommandozeile den Befehl:
esxcli storage core device setconfig -d naa.<diskID> –perennially-reserved=true
absetzen. Das ist dokumentiert in folgendem VMware KB Artikel: LINK
<diskID> steht hier für die 32-stellige DiskID. Dies ist für alle LUNs, die als Shared Storage für den Cluster zur Verfügung stehen sollen (und nur für die!) zu wiederholen.
Note: In einigen Dokumentationen steht, dass unter VMware 5.1 und besser dieses nicht mehr notwendig sei. Das hat sich aber als falsch erwiesen. Wir haben den Befehl mit Erfolg unter V5.5 abgesetzt.
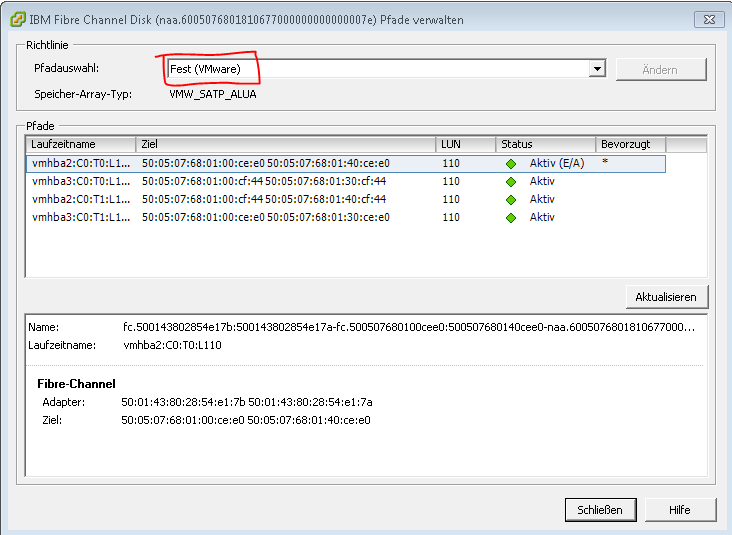
Bei mehrpfadigen Anbindungen sind auf dem VMware Host unter „Konfiguration->Speicher->Pfade verwalten“ für alle RAW Devices die Pfade von „Round Robin“ auf „Fest(VMWare)“ zu ändern.
Kapitel 2: Netzwerk und Firewall
Ein Cluster lässt sich nur von einem Domänenadministrator einrichten. D.h. er muss zwingend Mitglied eines AD sein. Steht er in einem vom AD abgetrennten Netz hinter einer Firewall, sind alle Ports zu öffnen, die ein Domänenjoin erfordert.
Dummerweise wird beim Joinen ein TCP Port zwischen 1024 und 65535 zufällig ausgehandelt, so dass der ganze Bereich offen sein muss, damit es funktioniert.
Anders ausgedrückt: Für den Domänenjoin muss die Firewall geöffnet werden.
Eine Portanalyse kann während der Installation mit dem Microsoft Tool „Portquery“ durchgeführtwerden (T:\Apps\Microsoft\PortQueryGUI).
Für den Betrieb eines SQL-Clusters benötigt man folgende Ports:
Windows Server Clustering –
| TCP/UDP | Port | Description |
| TCP/UDP | 53 | User & Computer Authentication [DNS] |
| TCP/UDP | 88 | User & Computer Authentication [Kerberos] |
| UDP | 123 | Windows Time [NTP] |
| TCP | 135 | Cluster DCOM Traffic [RPC, EPM] |
| UDP | 137 | User & Computer Authentication [NetLogon, NetBIOS] |
| UDP | 138 | DSF, Group Policy [DFSN, NetLogon, NetBIOS Datagram Service] |
| TCP | 139 | DSF, Group Policy [DFSN, NetLogon, NetBIOS Datagram Service] |
| UDP | 161 | SNMP |
| TCP/UDP | 162 | SNMP Traps |
| TCP/UDP | 389 | User & Computer Authentication [LDAP] |
| TCP/UDP | 445 | User & Computer Authentication [SMB, SMB2, CIFS] |
| TCP/UDP | 464 | User & Computer Authentication [Kerberos Change/Set Password] |
| TCP | 636 | User & Computer Authentication [LDAP SSL] |
| TCP | 3268 | Microsoft Global Catalog |
| TCP | 3269 | Microsoft Global Catalog [SSL] |
| TCP/UDP | 3343 | Cluster Network Communication |
| TCP | 5985 | WinRM 2.0 [Remote PowerShell] |
| TCP | 5986 | WinRM 2.0 HTTPS [Remote PowerShell SECURE] |
| TCP/UDP | 49152-65535 | Dynamic TCP/UDP [Defined Company/Policy {CAN BE CHANGED}] |
SQL Server –
| TCP/UDP | Port | Description |
| TCP | 1433 | SQL Server/Availability Group Listener [Default Port {CAN BE CHANGED}] |
| UDP | 1434 | SQL Server Browser |
| UDP | 2382 | SQL Server Analysis Services Browser |
| TCP | 2383 | SQL Server Analysis Services Listener |
| TCP | 5022 | SQL Server DBM/AG Endpoint [Default Port {CAN BE CHANGED}] |
| UDP | 49152-65535 | Dynamic TCP/UDP [Defined Company/Policy {CAN BE CHANGED}] |
Example [Multi-Subnet Setup]:
Subnet #1 – 10.10.33.192/26
Subnet #2 – 10.11.33.192/26
Active Directory Traffic:
| Source IP Range | 10.10.33.192/26, 10.11.33.192/26 |
| Destination IP Range | [Active Directory Servers] |
| TCP Ports | 53,88,389,464,636,3268,3269 |
| UDP Ports | 53,88,389,464 |
SCOM/SNMP Traffic:
| Source IP Range | [SCOM/SNMP Servers] |
| Destination IP Range | 10.10.33.192/26, 10.11.33.192/26 |
| TCP Ports | 162 |
| UDP Ports | 161,162 |
Windows Server Failover Clustering Traffic:
| Source IP Range | 10.10.33.192/26, 10.11.33.192/26 |
| Destination IP Range | 10.11.33.192/26, 10.10.33.192/26 |
| TCP Ports | 135,139,445,1433,2383,3343,5022,5985,5986 |
| UDP Ports | 137,138,445,1434,2382,3343,49152-65535 |
Windows Time Traffic:
| Source IP Range | 10.10.33.192/26, 10.11.33.192/26 |
| Destination IP Range | [NTP Servers] |
| TCP Ports | N/A |
| UDP Ports | 123 |
Client SQL Server Access Traffic:
| Source IP Range | [Client Application Servers] |
| Destination IP Range | 10.10.33.192/26, 10.11.33.192/26 |
| TCP Ports | 1433,2383 |
| UDP Ports | 1434,2382 |
Note: Wir haben noch die Ports 1028-1031 als gedropped ausgemacht und geöffnet. Danach lief alles einwandfrei.
Auf SQL Seite kann das später geändert werden im SQL Configuration Manager:
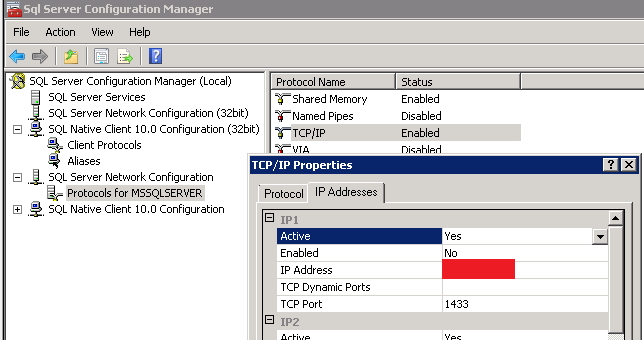
Ist die Firewall entsprechend vorbereitet, kann man beide Clusternodes joinen und in die vorbereitete OU verschieben – bzw. besser: Dort vorab die Computerkonten vorbereiten.
Kapitel 3: Clustering
Sind die Platten wie oben beschrieben vorbereitet, die Netzverbindung OK, AD Mitgliedschaft OK, Updates und Patche auf aktuellem Stand, VMware-Tools installiert und alle anderen Einstellungen aus der „Integrations-Bibel“ gemacht, kann man die Nodes clustern.
Erster Schritt: Installation des Features „Failover Clustering“ auf beiden Nodes.
Zweiter Schritt: Aufruf des Failover Cluster Managers aus den Tools des Server Managers:

Dritter Schritt: Aufruf von „Validate Configuration“. Hier hat Microsoft eine Testmephistik hinterlegt, die überprüft, ob ein Cluster funktionieren kann.
Man kann die Prerequisites jedes einzelnen Knotens überprüfen (dann erhält man Warnings für alle clusterspezifischen Einstellungen, die nicht getestet werden können) oder man bindet beide Knoten in den Test ein, dann wird ein Clustering simuliert und Warnings und Errors für alle Unstimmigkeiten ausgegeben.
(!) Error – Er reklamiert das jeweils letzte der shared Devices und setzt dieses auf offline.
Grund: Der Clustermanager versucht die jeweils letzte Platte als Quorum einzurichten. Haben wir gemäß unserer Bibel das CD-ROM-Laufwerk auf Z: verschoben, so erkennt er die letzte Platte als unzulässig.
Lösung: Diesen Fehler einfach ignorieren. Ist es der einzige, kann man mit „Create Cluster“ auf dem ersten Node beginnen. Auch hier mahnt er einige Male die fehlende Quorum Disc an; die kann im Nachgang dann aber auf der dafür vorgesehenen Partition eingerichtet werden und alles ist gut.
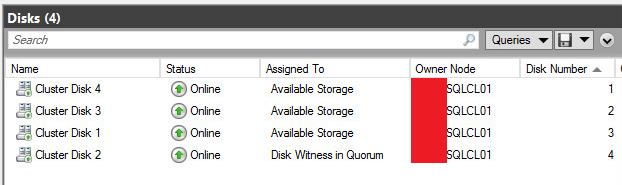
So sehen die Platten im Cluster Manager nach Einrichten des Quorums am Ende aus.
Der komplette Vorgang der Clustereinrichtung inkl. Integration des zweiten Nodes wird hier vorausgesetzt und ist Thema einer anderen Anleitung.
Quellen:
Einrichten für das Failover-Clustering
Anhang, Schalttest:
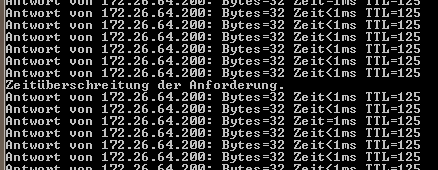
So sieht das Umschalten des Clusters beim Runterfahren des 1. Nodes von außen aus.
Weitere Tätigkeiten:
CAU – Cluster Aware Updating
http://www.projectleadership.net/blogs_details.php?id=2706