In den Artikeln 16.1 (Nagios und SNMP) bzw. 16.2 (checkMK) ging es um das “klassische” Monitoring von Daten via Push/Pull verfahren welches statisch alle X Sekunden/Minuten entsprechende Ergebnisse liefert. Das funktioniert gut, kann aber ergänzt werden um Livedaten welche via METRIKEN abgegriffen werden und damit in Echtzeit dargestellt werden. Das Abgreifen dieser Metriken wird häufig im Container-Umfeld mit dem OpenSource Projekt Prometheus durchgeführt. Die Darstellung dann in ansprechenden Graphen mit Grafana.
Das Datenabgriff wird dabei realisiert durch sog. “Node-Exporter” welche es unter Github für diverse Anwendungsfälle gibt. EINEN gibt es auch für Nutanix!
Der Testaufbau in meinem Homelab sieht dabei nun wie folgt aus:
NutanixCluster <- Prometheus <- Grafana
192.168.10.80 192.168.10.123 192.168.10.100
Nutanix CE Ubuntu 18.04 LTS Ubuntu 18.04 LTS
Prometheus 2.2.1 Grafana 7.0.4
GO 1.10
Voraussetzungen:
- Neuen User in Nutanix anlegen welcher nur VIEWER Rechte hat

2. Installation von Prometheus auf einem Ubuntu 18.04 LTS mit lauffähigen GO!
Gute Quellen sind u.a. hier zu finden bzw. hier.
3. Installation von Grafana 7.x auf einem Ubuntun 18.04 LTS
Gute Quellen sind u.a. hier zu finden.
Start der Anbindung
- Wir laden das GO Binary für den Nutanix-Exporter auf den Prometheus Rechner in das GO/BIN Verzeichnis
Wir testen gleich mal ob das Binary im go/bin Verzeichnis funktioniert und die entsprechenden Hilfe-Parameter auswirft mit –help.
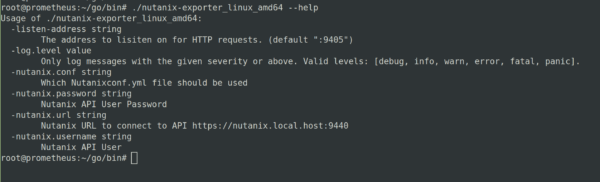
SO sollte es aussehen. Probieren wir nun gleich mal aus ob wir mit unserem VIEWER User aus dem Cluster Metriken ziehen können. Geben wir keinen Port an, laufen diese auf dem Prometheus Server auf Port 9405 auf. Wir testen gleich mal einen anderen Port (Was für mehrere Cluster notwendig wird).

Der Cluster kann via IP oder auch DNS Eintrag angesprochen werden. Username/Password lässt sich noch eleganter mit Variablen erledigen. Das Ergebnis sollte auf dem Prometheus Server jetzt auf Port :9494 auflaufen…
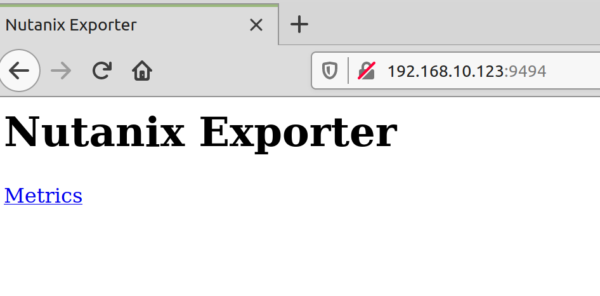
BINGO. Ein Klick auf Metrics liefert brauchbare Ergebnisse!
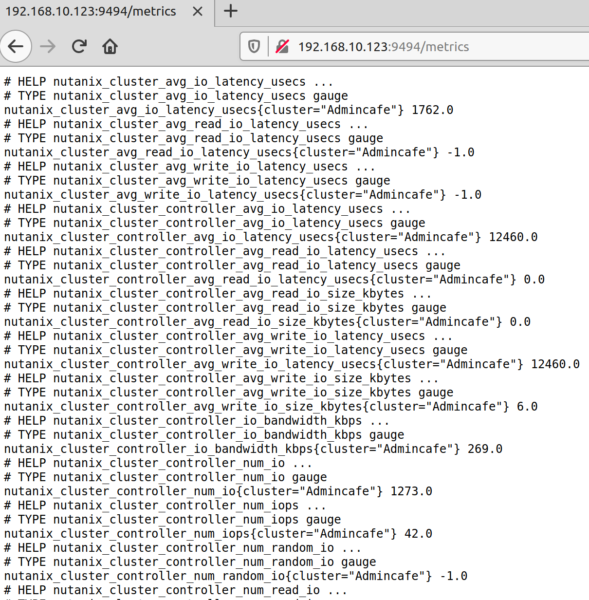
Jetzt kommen wir zwar dran, aber nur manuell! Wir bauen aus diesem Aufruf jetzt ein Shell Script was das automatisiert durchführt. Das Shell Script wiederum hängen wir unter /etc/systemd/system als neuen SERVICE ein, so dass die Prüfung automatisch mit jedem Server Reboot wieder losläuft!
- Bash-Script anlegen im Ordner /go/bin oder wo auch immer gewüncht mit beispielhaft folgendem Inhalt

2. Anlegen eines Services unter /etc/systemd/system mit folgendem Inhalt:
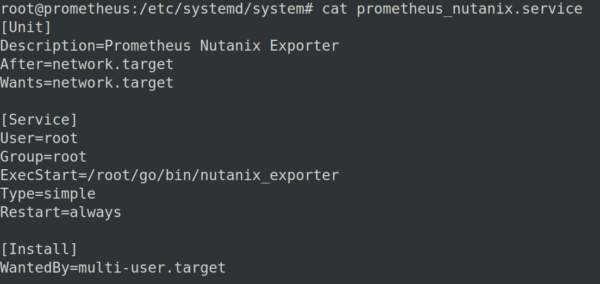
Das Anlegen von Services unter Systemd mit systemctl enable service name erfolgt also im Ordner /etc/systemd/system mit systemctl enable prometheus_nutanix.service.
Wir können das ganze nach einem Systemreboot kontrollieren via
systemctl status prometheus_nutanix.service und sollten einen laufenden Service erhalten!

Soweit können wir nun Metriken auf Port :9405 oder wo auch immer angegeben darstellen. Für die Schnittstelle Prometheus/Grafana reicht das aber nicht. Der Exporter muss in Prometheus aus sog. TARGET noch definiert werden!
Dazu wird die /etc/prometheus/prometheus.yml um folgenden Abschnitt ergänzt und Prometheus neu gestartet!

Anschliessend kontrollieren wir in der GUI von Prometheus auf Port :9090 ob das neue Target sauber angezeigt wird und die Metrik URL in GRÜN abliefert.
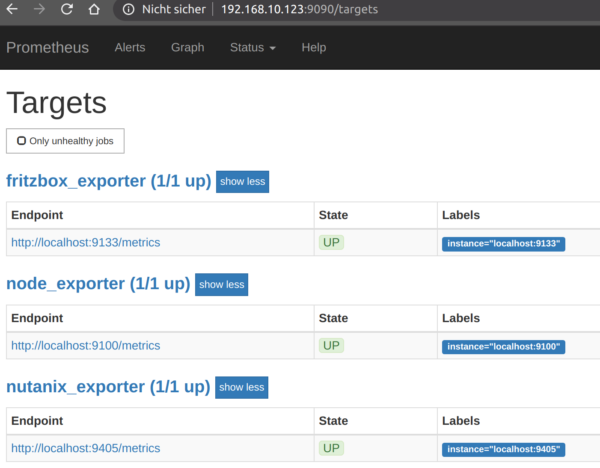
GUT! Der Prometheus Teil ist damit beendet und wir können uns den schönen Seiten von GRAFANA zuwenden.
- Wir binden in Grafana nun Prometheus als Datenquelle mit ein
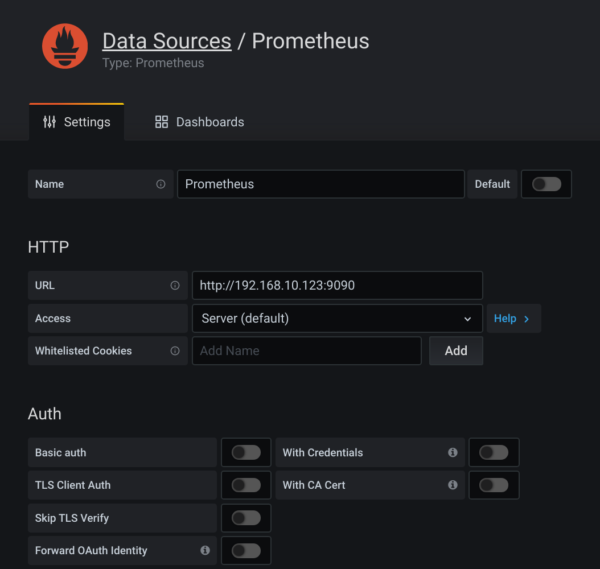
Anschliessend können wir neue Dashboards anlegen und die METRIKEN auswählen unter Prometheus/Nutanix.(bzw. Exportername aus der Prometheus Config)
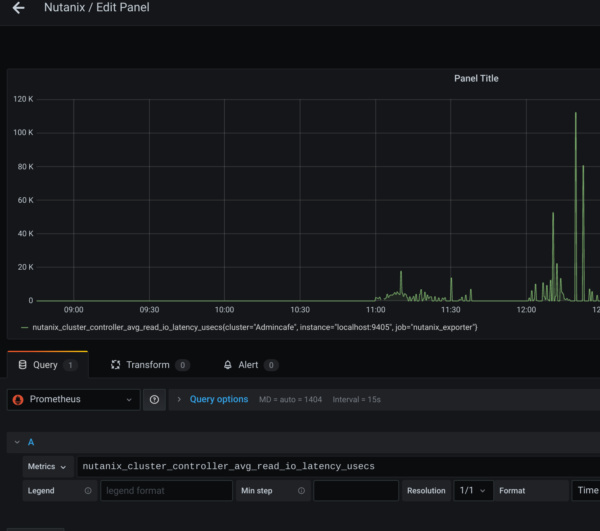
Hinweis! Es macht also SINN die Nutanix-Exporter in Prometheus je Cluster sauber zu benennen, ansonsten wird es hier mit vielen Metriken zum auswählen SEHR unschön!
Für den Anfang habe ich mal ein Sample Dashboard mit einigen Paramtern wie VMS je Node, CPU und Memory Nutzung im Cluster, Storage X free Gigabyte gebaut…
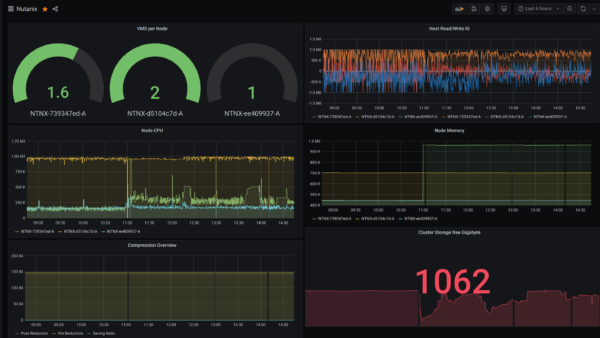
Wer damit starten möchte etc. kann das entsprechende JSON File in meinem Github Repo hier runterladen und in Grafana entsprechend importieren.
Am Ende noch ein Tip zum Handling der Metriken. Ich habe die ganze Sammlung der Metriken aus der Prometheus Metrikseite von Nutanix in ein Textfile gespeichert. Das lässt sich dann prima via Sublime/notepad++ durchsuchen.

Die Werte hinter HELP und TYPE sind uninteressant! Das NAME der Metrik steht hier vor den geschweiften Klammern mt dem Wert….diesen kann man aus dem Textfile gut kopieren und in Grafana dann unter Metrik einfügen. Gibt es dann mehrere Subwerte zeigt Grafana diese entsprechend an und wir können auswählen…
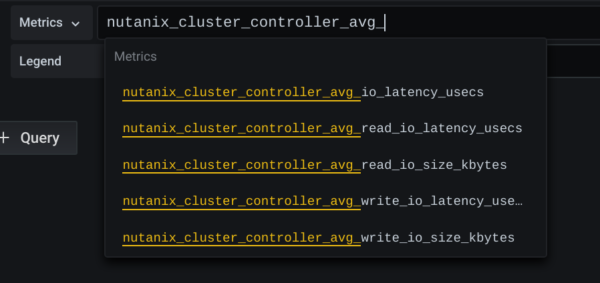
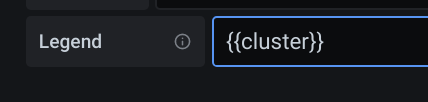
Die Legenden zeigen unter Grafana immer den Namen der Metrik defaultmässig an. Das kann man
a) manuell überschreiben
b) Variablen nutzen wie z.B. {{cluster}} oder {{node}}
Einige Werte werden unschön lesbar in BYTE angeliefert. Der Output lässt sich aber leicht via /1024/1024/1024 etc. in MB/GB/TB umrechnen

Viel Spass beim erstellen von Dashboards…….